The Databricks Lakehouse Platform is a popular data platform. It is fully based on Apache Spark. In fact, the people who created Apache Spark found the company to offer a commercial data platform. In addition, they heavily promote Delta Lake, a storage format for files that uses versioned Parquet files and a transaction log to provide ACID transactions.
Databricks is a full-featured platform that runs on top of one of the three cloud providers: AWS, GCP, Azure. On Azure, Microsoft is your business partner, so you don't have to sign a separate contract with Databricks. In any case, the cloud provider resources (such as object storage, compute engines, virtual network configuration, access control) are used by the platform. The platform basically runs in compute engines and uses futher compute engines to manage workloads.
Databricks is very popular among Data Scientists. It has an integrated environment, collaborative notebooks, and managed and scalable resources. But is it also a good choice for a general Data Mesh platform? Let's dive into the components that we would use for Data Mesh.
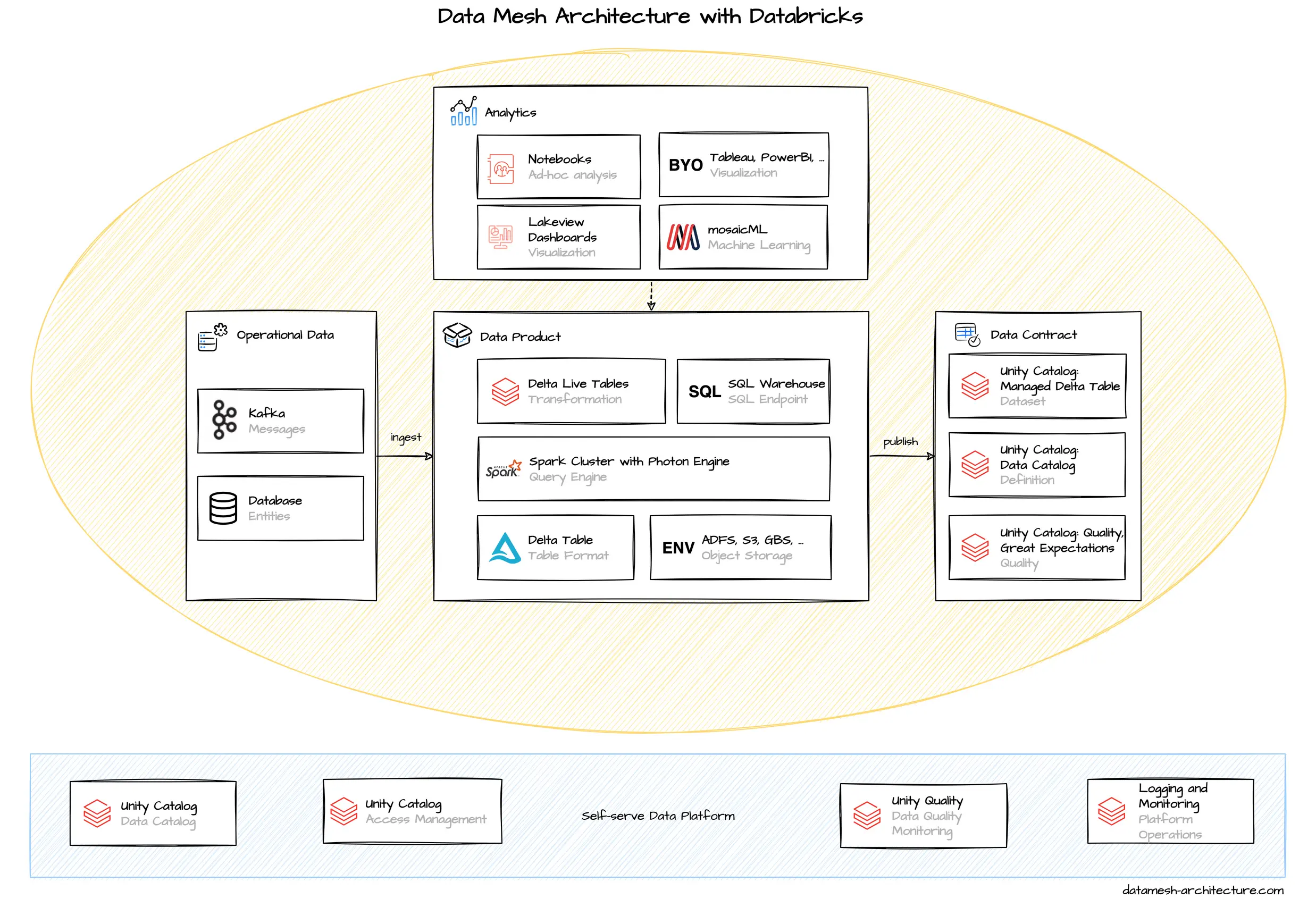
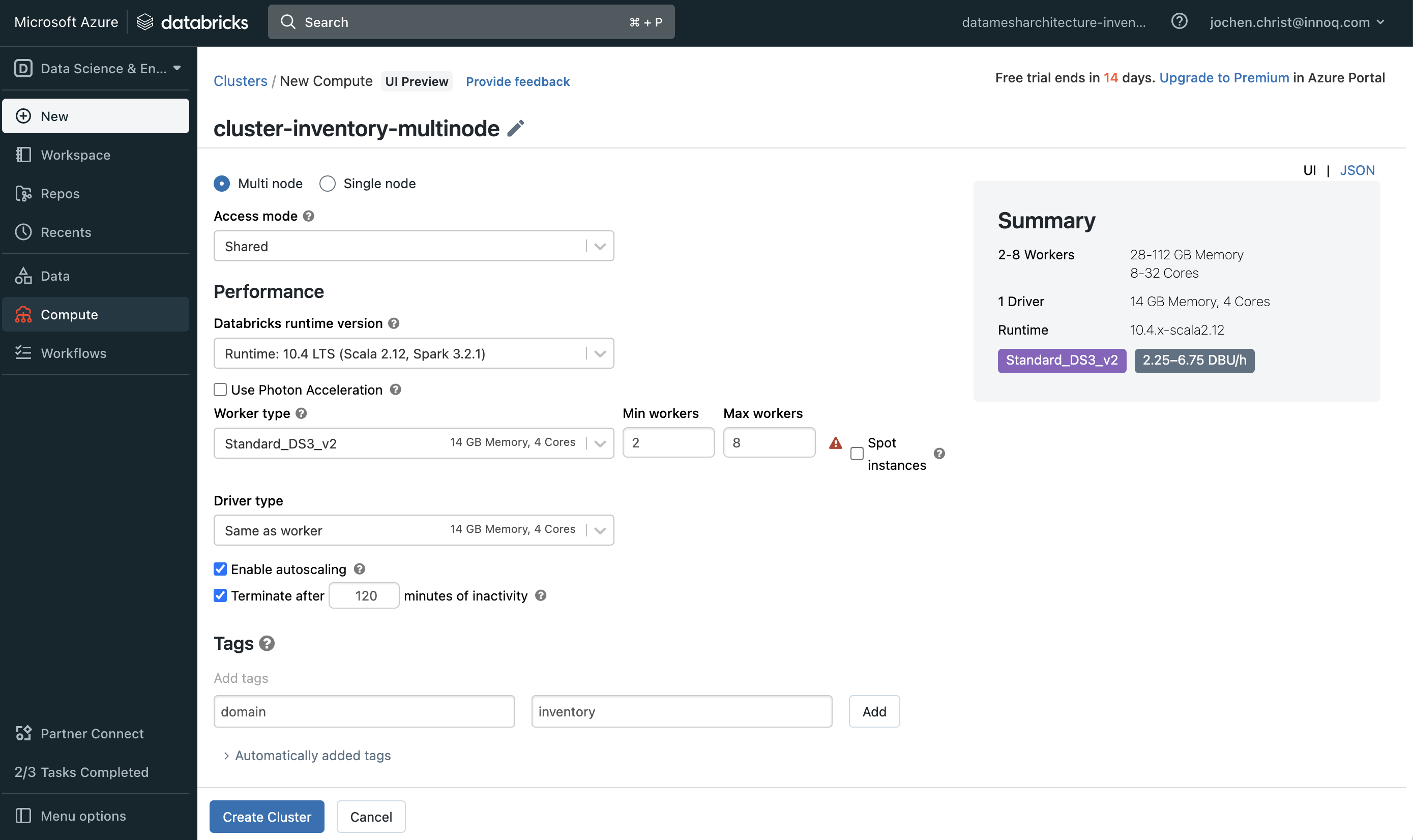
The starting point in Databricks is the workspace. Each team typically creates their own workspace, and in their workspace their own clusters for their computing needs. These clusters come with a configured Spark and Photon Runtime as query engine. The clusters are mapped to cloud provider's compute instances and can be scaled elastically with the workloads to execute code and queries.
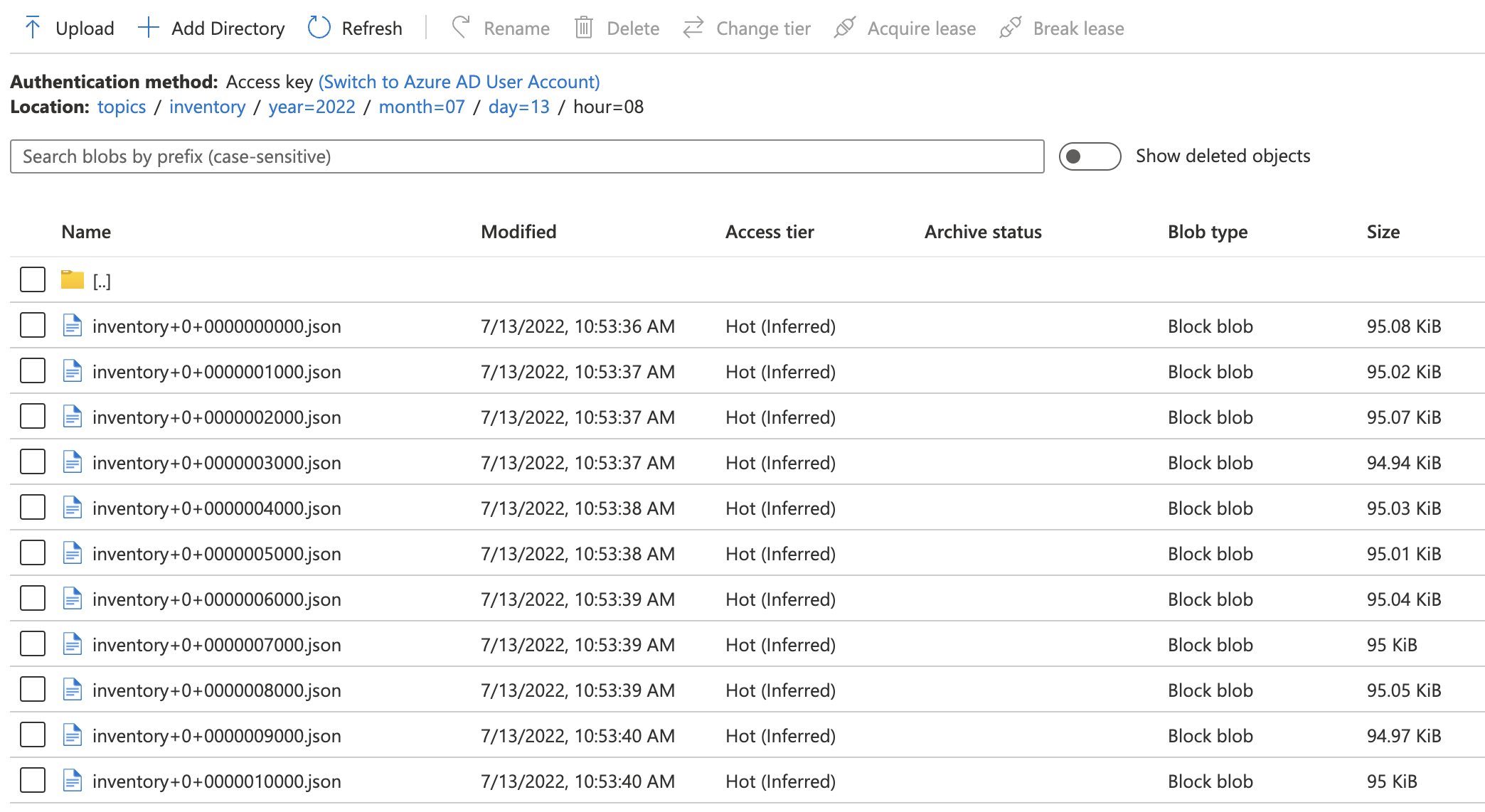
Data are always stored as files. To ingest data, data need to be written to an object store (S3, Cloud Storage, ADLS) by a provider in an appropriate format, such as Parquet, JSON, CSV or Delta. Transformed and intermediary data are usually written to delta files in a backing object storage, but Spark supports all other formats, if required. Delta files represent a table structure, and are optimized for columnar access. These delta tables also support insert, update and delete operations.
With Spark, most of the data engineering is typically coded in Jupyter-like notebooks using Python, Scala, R, or Spark SQL code. The notebooks are interactive, meaning that cells can be executed directly and iteratively. With Databricks, data import, cleaning, transformation, explorative analytics, and machine learning is coded in notebooks. The code can usually be managed in a connected Git repository.
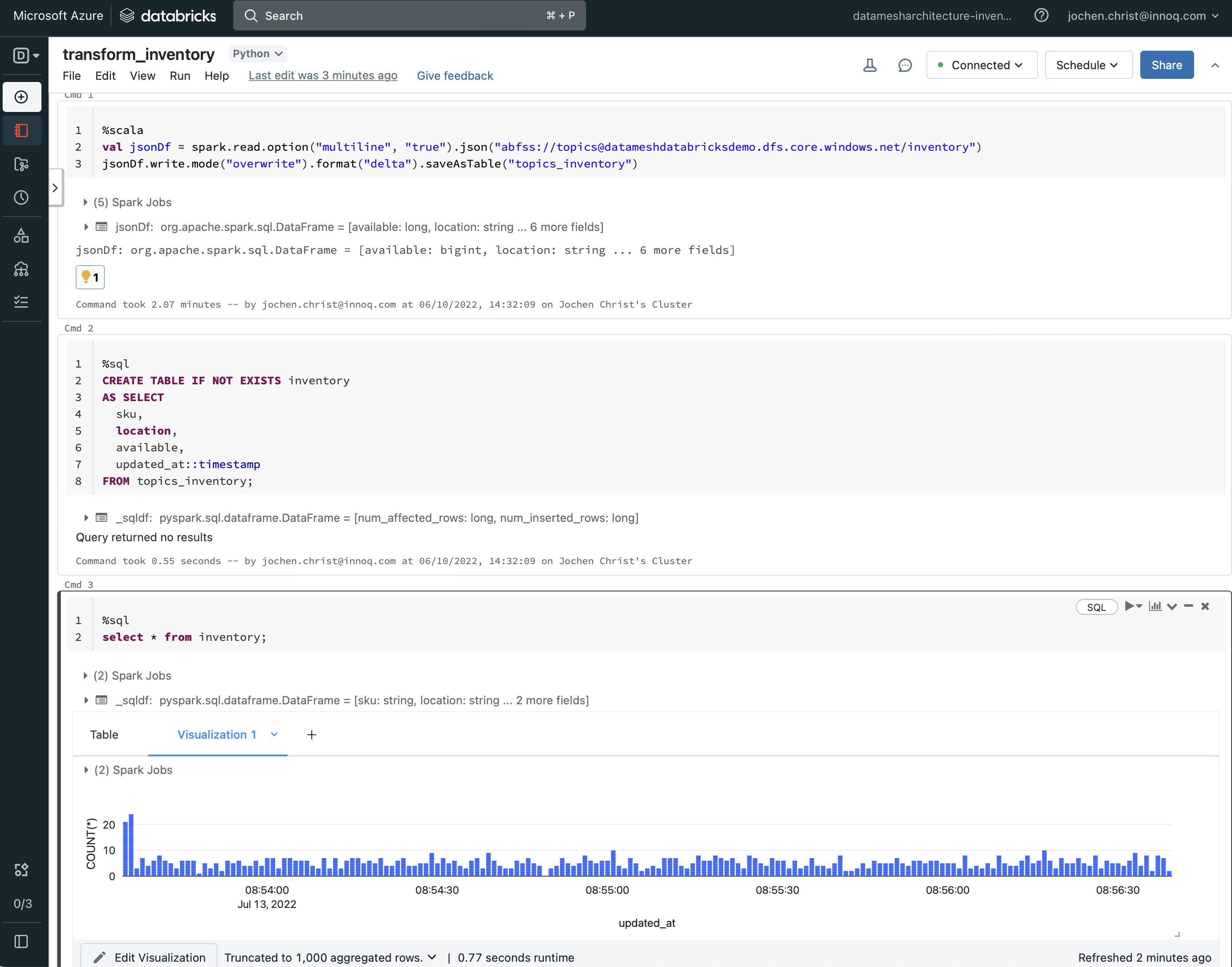
Notebooks are also the default way to build data products. Delta live tables are used to build managed pipelines with notebooks, for scheduled or continuous tranformations. Notebooks include the code that imports data, transforms and aggregates, performs validation, includes tests and quality metrics and finally creates a data set in the export format. Through Spark, there is a lot of freedom how to operate with the data and available libraries (especially for Python) provide unlimited capabilities. For example, a data product notebook may also include a step to generate and publish a data product description for documentation, including dynamic information on the current data set. Also, policy automation can be implemented this way, e.g. by including a shared library that performs anonymization procedures on tagged columns.
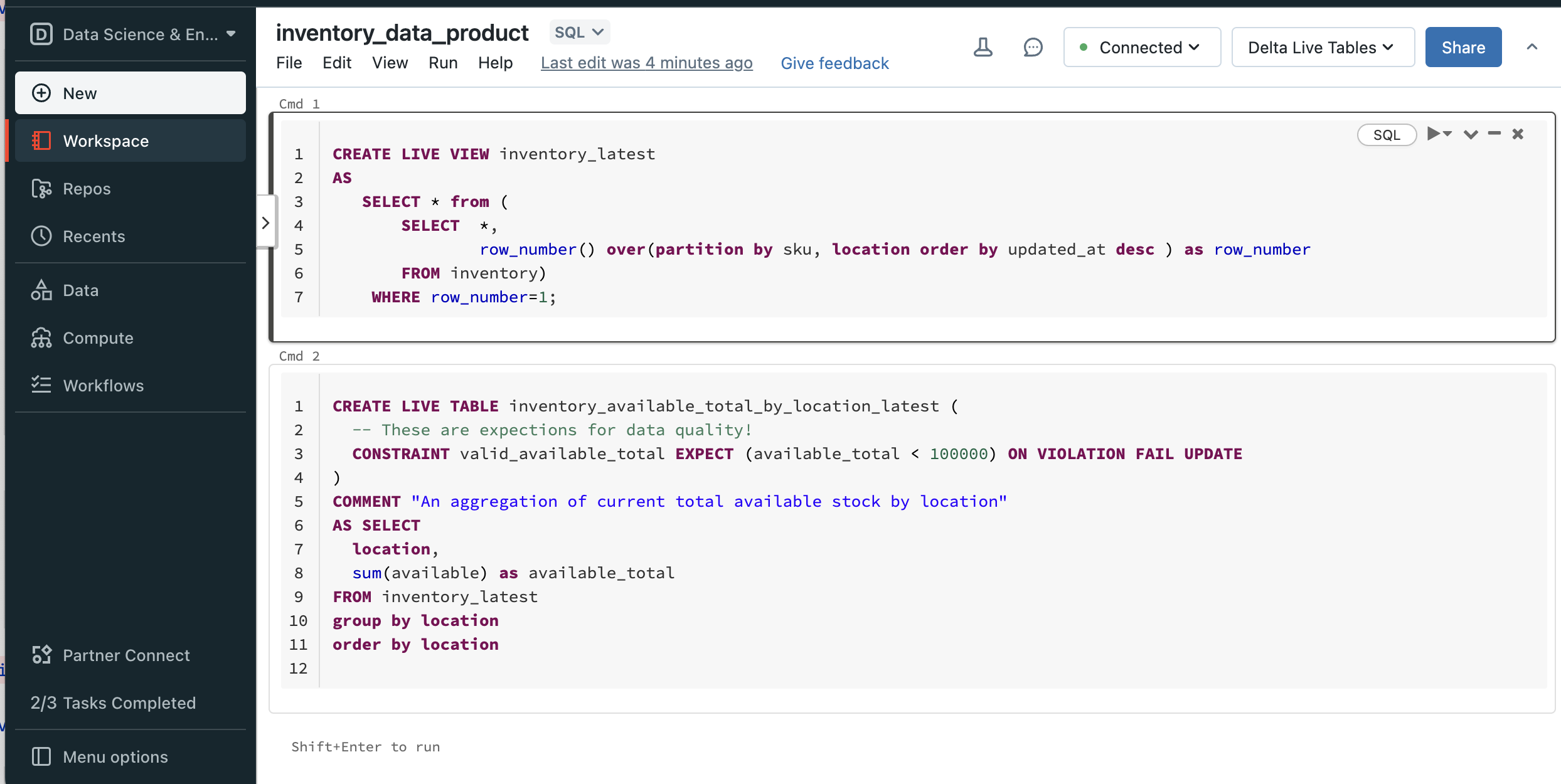
A metastore maps table structures to underlying files in the object store. This allows you to execute structured SQL queries to files and to evolve the schema over time. Traditionally, most Data Lakes rely on Apache Hive, a metastore coming from Hadoop. As Hive has some drawbacks (e.g., difficult to install and maintain, requires a relational database). Databricks recently implemented an alternative to Hive, the Unity Catalog, a proprietary metastore for Databricks. A Unity Catalog can be shared across workspaces, as it is backed by a simple object store.
All tables and columns are registered in the metastore. This makes the metastore a candidate for a data catalog to publish, manage and discover data products. A frequent challenge with a metastore as a data catalog is that it quickly becomes clattered and convoluted with internal and irrelevant data structures, important data products may perish. Unity Catalog is the default standard on Databricks to overcome those challenges.
Unity Catalog on the Databricks platform is a unified data governance solution designed to enhance data security, compliance, and discoverability across an organization. It centralizes data governance, allowing for consistent policy application and management of data access at scale. Key features include fine-grained access control, unified metadata management, and comprehensive auditing capabilities. This integration ensures that data products are managed in accordance with organizational policies, promotes efficient data operations, and supports a culture of data-driven innovation. By streamlining data governance and data product management within Databricks, Unity Catalog facilitates a secure, compliant, and collaborative data ecosystem.
Databricks comes with special view for data analysts that prefer to work with SQL. Historically, it was just an SQL endpoint to access data on Databricks, but additional services were added, providing a more data-warehouse-like experience. SQL features can be used for data mesh capabilities: Software engineers can use SQL for simple analytics, without the need to work with notebooks, and they can leverage SQL dashboards and visualizations to gain insights. SQL alerts can be used for basic data quality monitoring, as they run queries regularly and send notifications to a when the queries trigger. Databricks provides build-in dashboards for visualization. Additionally Lakeview was introduced to give business user a way to wrangle and visualize data based on natural language. The SQL warehouse provides an HTTP or JDBC connection endpoint to publish data products for external applications as well, such as Tableau or PowerBI.
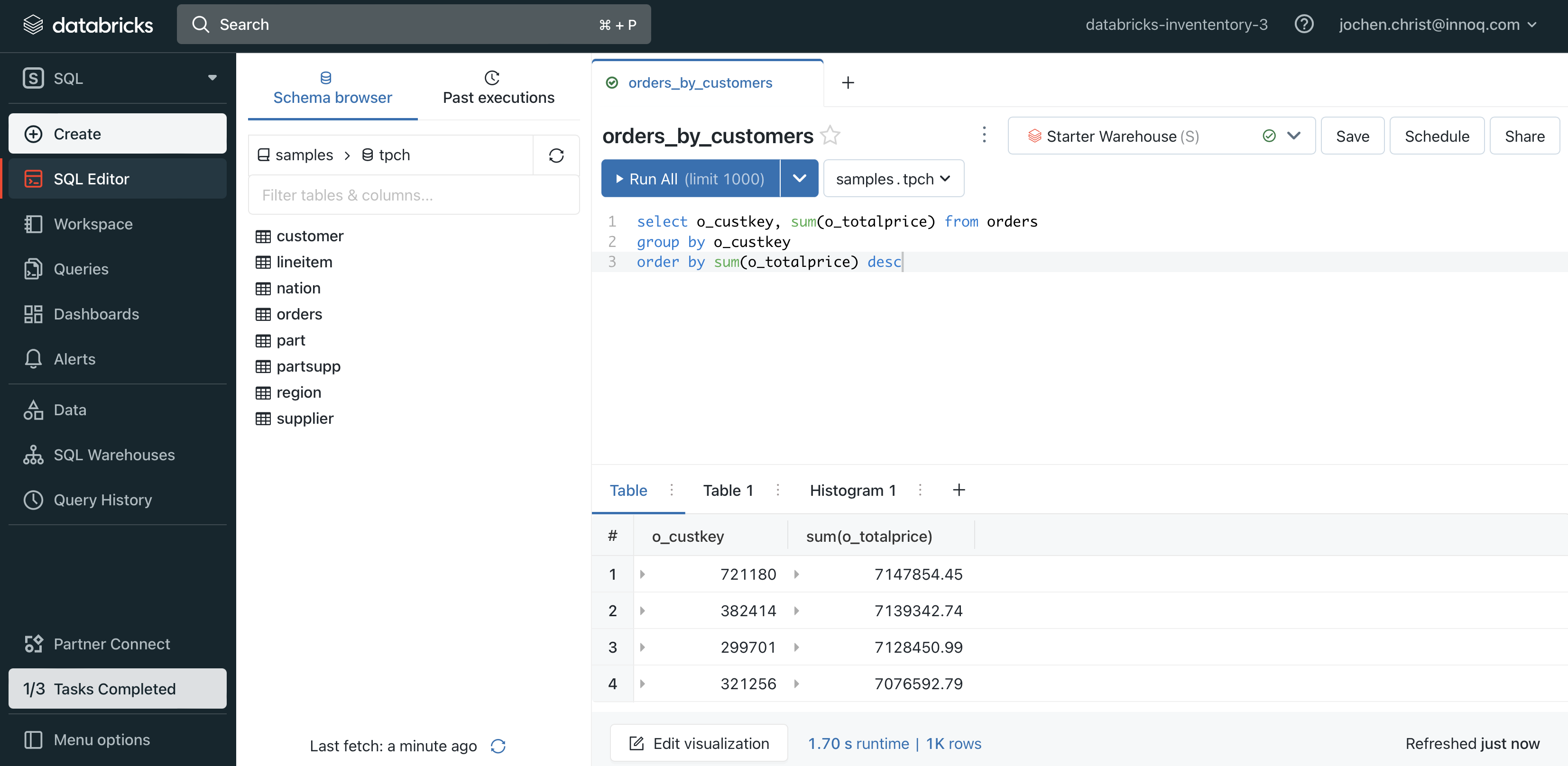
Databricks is probably the most powerful data platform available today, and it clearly can act as a foundation for a data mesh platform.
It is optimized for data scientists that work a lot with notebooks, but it also
invested in further experiences.
As it tightly interacts with the cloud provider for data storage and access management, organization and administration will take a while to master for the data platform team, and it must be set up appropriately from the beginning.
With its unified data platform Databricks provides access to data and AI to different personas. It is great for data ingestion and complex ETL pipelines for Data Engineers, SQL warehousing capabilities for Business Analysts, Datascience and ML workoads for Datascientists.
All of those components are supported by an assistant, to give users access based on natural language.
