How To Build a Data Product with Databricks

April 3, 2024
Today's data engineering shifted from building monolithic data pipeline structures to modular data products.
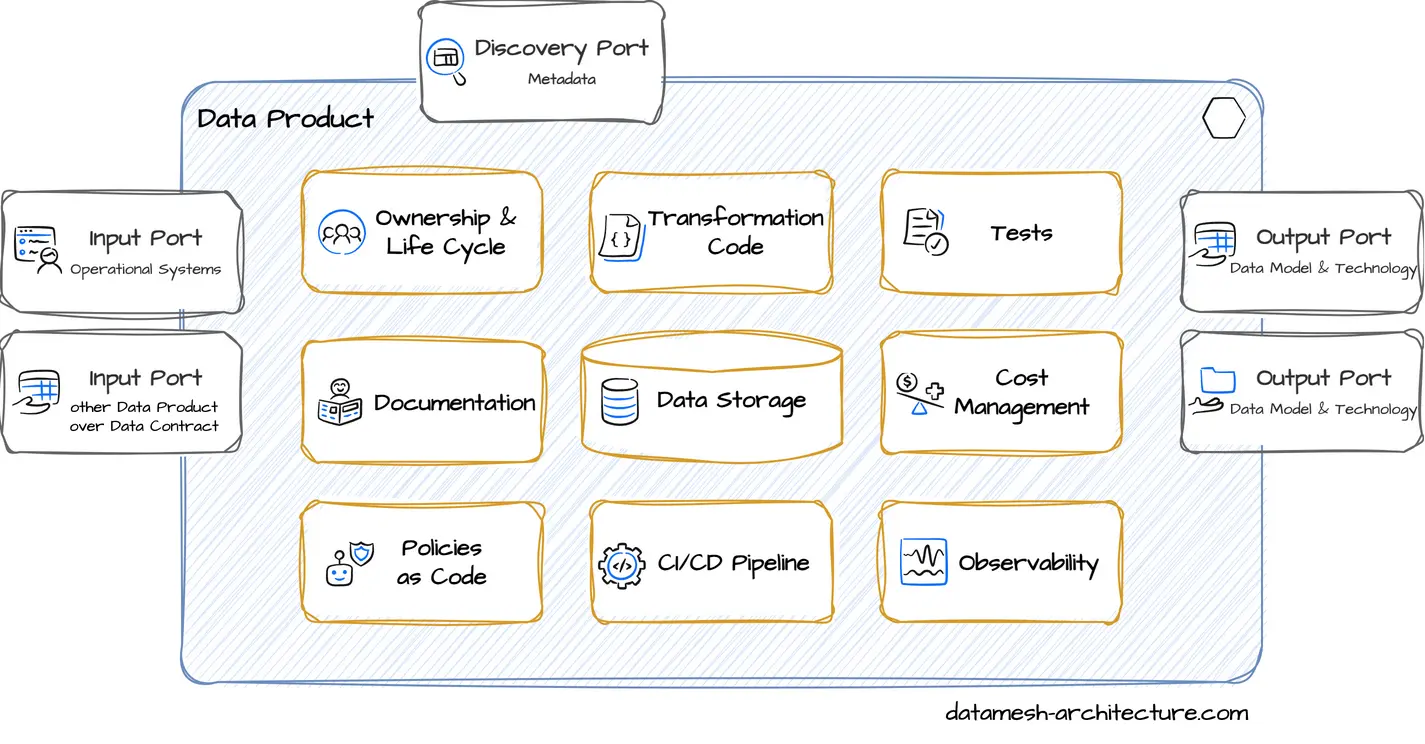
A data product is the deliverable that contains everything around a business concept to fulfill a data consumer's need:
- tables to actually store data
- code that transform data
- tests to verify and monitor that data is correct
- output ports to make data accessable
- input ports to ingest data from source systems or access other data products
- data contracts to describe the API
- documentation
- meta information, such as ownership
A data product is usually managed in one Git repository.
Databricks is one of the most popular modern data platforms, now how can we engineer a professional data product with Databricks?
In this article, we will use Data Contracts and the new Databricks Asset Bundles that are a great fit to implement data products. All source code of this example project is available on GitHub.
Define the Data Contract
Before we start implementing, let's discuss and define the business requirements. What does our data consumer need from us, what is their use case, what do they expect as a data model. And we need to make sure, that we understand and share the same semantics, quality expectations, and expected service levels.
We call this approach contract-first. We start designing the interface of the provided data model and its metadata as a data contract. We use the data contract to drive the implementation.
In our example, the COO of an e-commerce company wants to know if there is an issue with articles that are not sold for a longer period, i.e., articles with no sale during the last three months, the so-called shelf warmers.
In collaboration with the data consumer, we define a data contract as YAML, using the Data Contract Specification:
dataContractSpecification: 0.9.3
id: urn:datacontract:fulfillment:stock-last-sales
info:
title: Last Sales
version: 1.0.0
description: |
The data model contains all articles that are in stock.
For every article the last sale timestamp is defined.
owner: Fulfillment
contact:
name: John Doe (Data Product Owner)
url: https://teams.microsoft.com/l/channel/19%3Ad7X0bzOrUrZ-QAGu0nTxlWACe5HOQ-8Joql71A_00000%40thread.tacv2/General?groupId=4d213734-d5a1-4130-8024-00000000&tenantId=b000e7de-5c4d-41a2-9e67-00000000
servers:
development:
type: databricks
host: dbc-abcdefgh-1234.cloud.databricks.com
catalog: acme
schema: stock-last-sales
terms:
usage: >
Data can be used for reports, analytics and machine learning use cases.
Order may be linked and joined by other tables
limitations: >
Not suitable for real-time use cases.
billing: free
noticePeriod: P3M
models:
articles:
description: One record per article that is currently in stock
type: table
fields:
sku:
description: The article number (stock keeping unit)
type: string
primary: true
pattern: ^[A-Za-z0-9]{8,14}$
minLength: 8
maxLength: 14
example: "96385074"
quantity:
description: The total amount of articles that are currently in stock in all warehouses.
type: long
minimum: 1
required: true
last_sale_timestamp:
description: The business timestamp in UTC when there was the last sale for this article. Null means that the article was never sold.
type: timestamp
processing_timestamp:
description: The technical timestamp in UTC when this row was updated
type: timestamp
required: true
servicelevels:
availability:
percentage: 99.9%
retention:
period: 1 year
freshness:
threshold: 25 hours
timestampField: articles.processing_timestamp
frequency:
description: Data is updated once a day
type: batch
cron: 0 0 * * *
examples:
- type: csv
data: |
sku,quantity,last_sale_timestamp,processing_timestamp
1234567890123,5,2024-02-25T16:16:30.171798,2024-03-25T16:16:30.171807
2345678901234,10,,2024-03-25T15:16:30.171811
3456789012345,15,2024-03-02T12:16:30.171814,2024-03-25T14:16:30.171816
4567890123456,20,,2024-03-25T13:16:30.171817
5678901234567,25,2024-03-08T08:16:30.171819,2024-03-25T12:16:30.171821
6789012345678,30,,2024-03-25T11:16:30.171823
7890123456789,35,2024-03-14T04:16:30.171824,2024-03-25T10:16:30.171826
8901234567890,40,,2024-03-25T09:16:30.171830
9012345678901,45,2024-03-20T00:16:30.171833,2024-03-25T08:16:30.171835
0123456789012,50,,2024-03-25T07:16:30.171837
quality:
type: SodaCL
specification:
checks for articles:
- row_count > 1000
The dataset will contain all articles that currently are in stock and it includes the last_sale_timestamp, the attribute that is most relevant for the COO.
The COO can easily filter in their BI tool (such
as PowerBI, redash, ...) for articles with last_sale_timestamp older than three months.
Terms and service Level attributes make it clear that the dataset is update daily at midnight.
Create the Databricks Asset Bundle
Now it is time to develop a data product that implements this data contract. Databricks recently added the concept of Databricks Asset Bundles that are a great fit to structure and develop data products. As time of writing in March 2024, they are in Public Preview, meaning ready for production-use.
Databricks Asset Bundles include all the infrastructure and code files to actually deploy data transformations to Databricks:
- Infrastructure resources
- Workspace configuration
- Source files, such as notebooks and Python scripts
- Unit tests
The Databricks CLI bundles these assets and deploys them to Databricks Platform, internally it uses Terraform. Asset Bundles are well-integrated into the Databricks Platform, e.g., it is not possible to edit code or jobs directly in Databricks, which enables a strict version control of all code and pipeline configuration.
Bundles are extremely useful, when you have multiple environments, such as dev, staging, and production. You can deploy the same bundle to multiple targets with different configurations.
To create a bundle, let's init in a new bundle:
databricks bundle init- Template to use: default-python
- Unique name for this project: stock_last_sales
- Include a stub (sample) notebook in 'stock_last_sales/src': yes
- Include a stub (sample) Delta Live Tables pipeline in 'stock_last_sales/src': no
- Include a stub (sample) Python package in 'stock_last_sales/src': yes
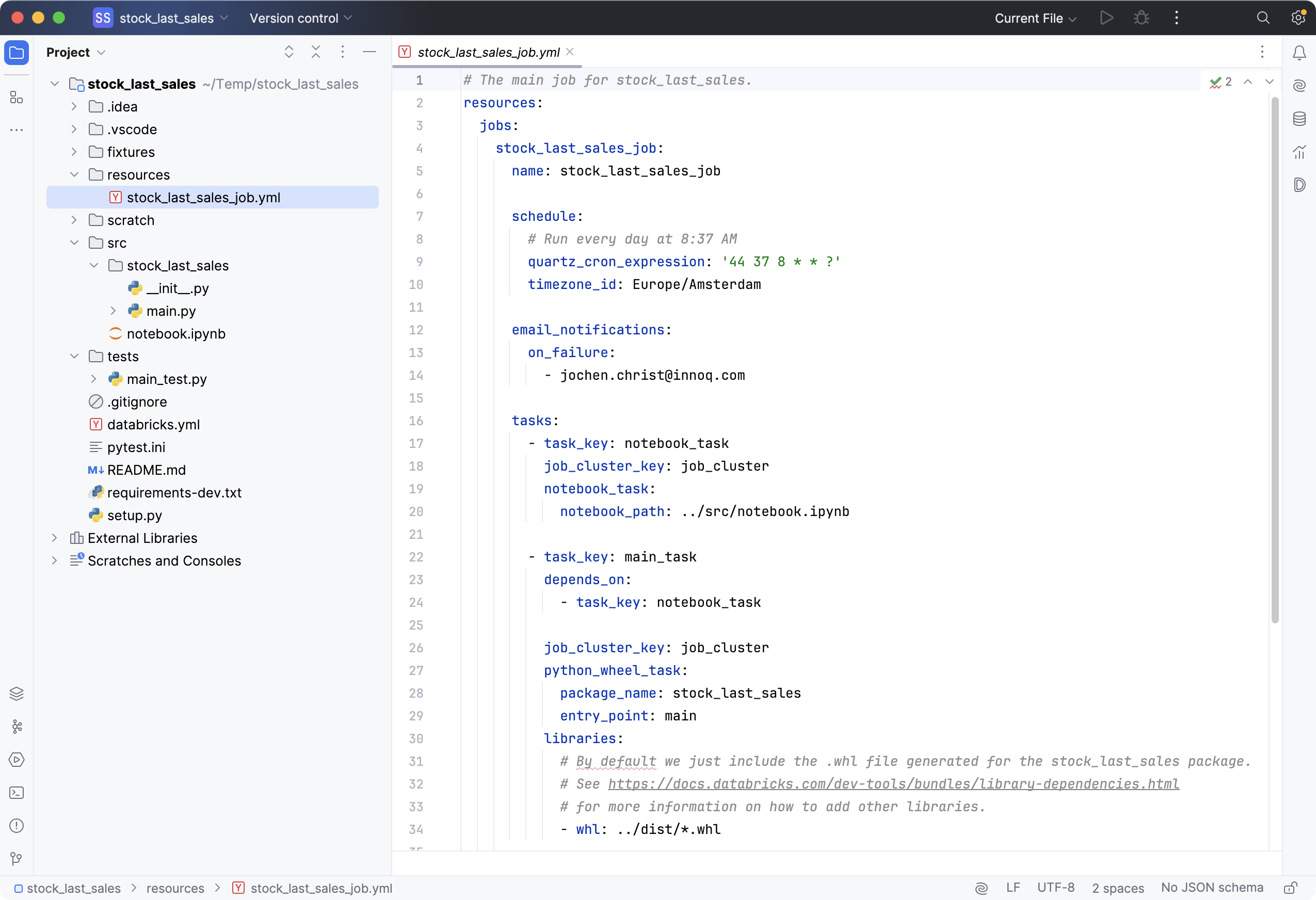
When we look into the bundle structure, let's have a quick look at the most relevant files:
- databricks.yml The bundle configuration and deployment targets
- src/ The folder for the transformation code
- tests/ The folder to place unit tests
- resources/ The job definition for the workflow definition
Note: We recommend to maintain an internal bundle as template that incorporates the company's naming conventions, global policies, best practices, and integrations.
With asset bundles, we can write our code locally in our preferred IDE, such as VS Code (using the Databricks extension for Visual Studio Code), PyCharm, or IntelliJ IDEA (using Databricks Connect).
To set up a local Python environment, we can use venv and install the development dependencies:
python3.10 -m venv .venv
source .venv/bin/activate
pip install -r requirements-dev.txtGenerate Unity Catalog Table
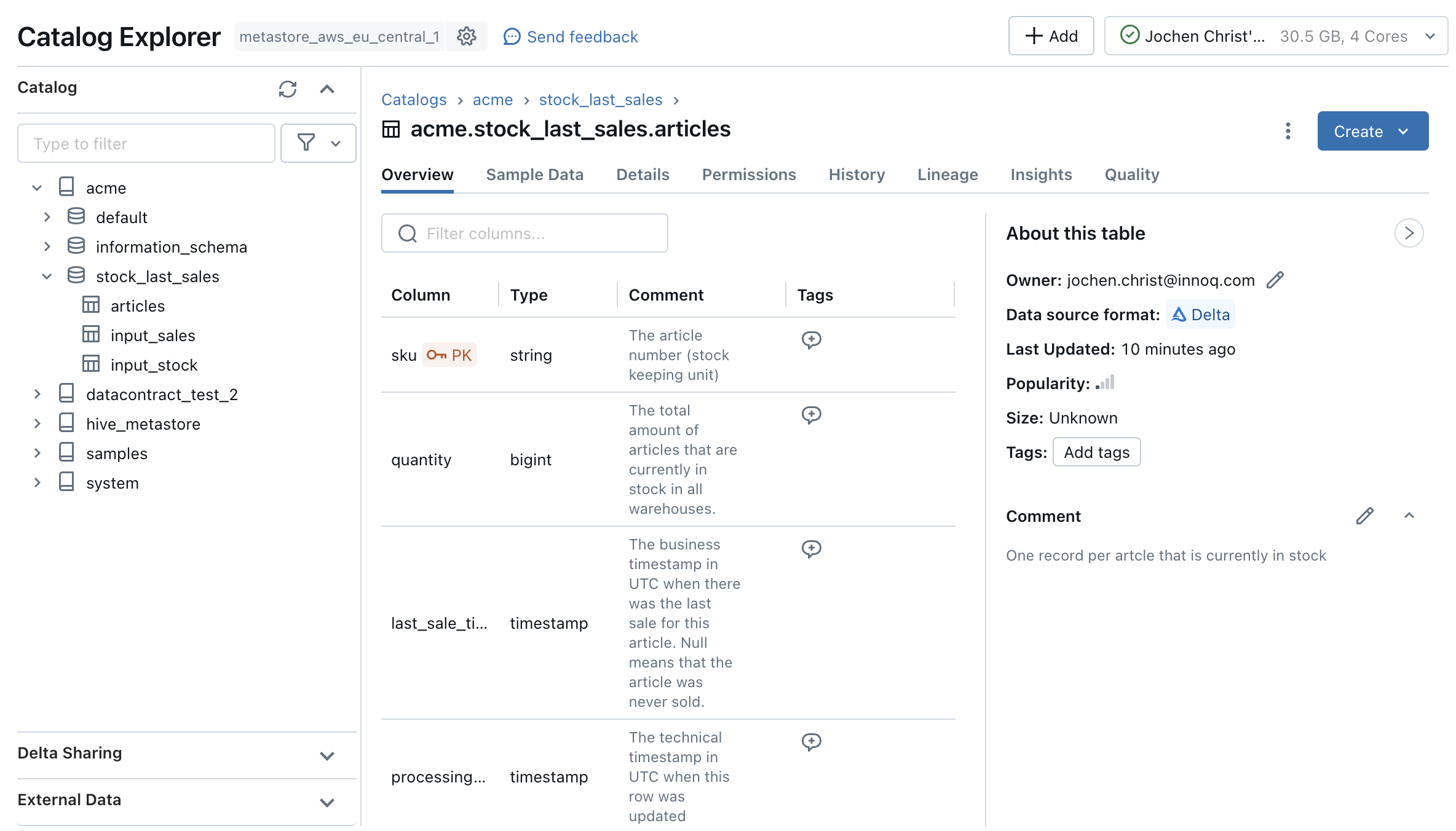
How do we organize the data for our data product? In this example, we use Unity Catalog to manage storage as managed tables. On an isolation level, we decide that one data product should represent one schema in Unity Catalog.
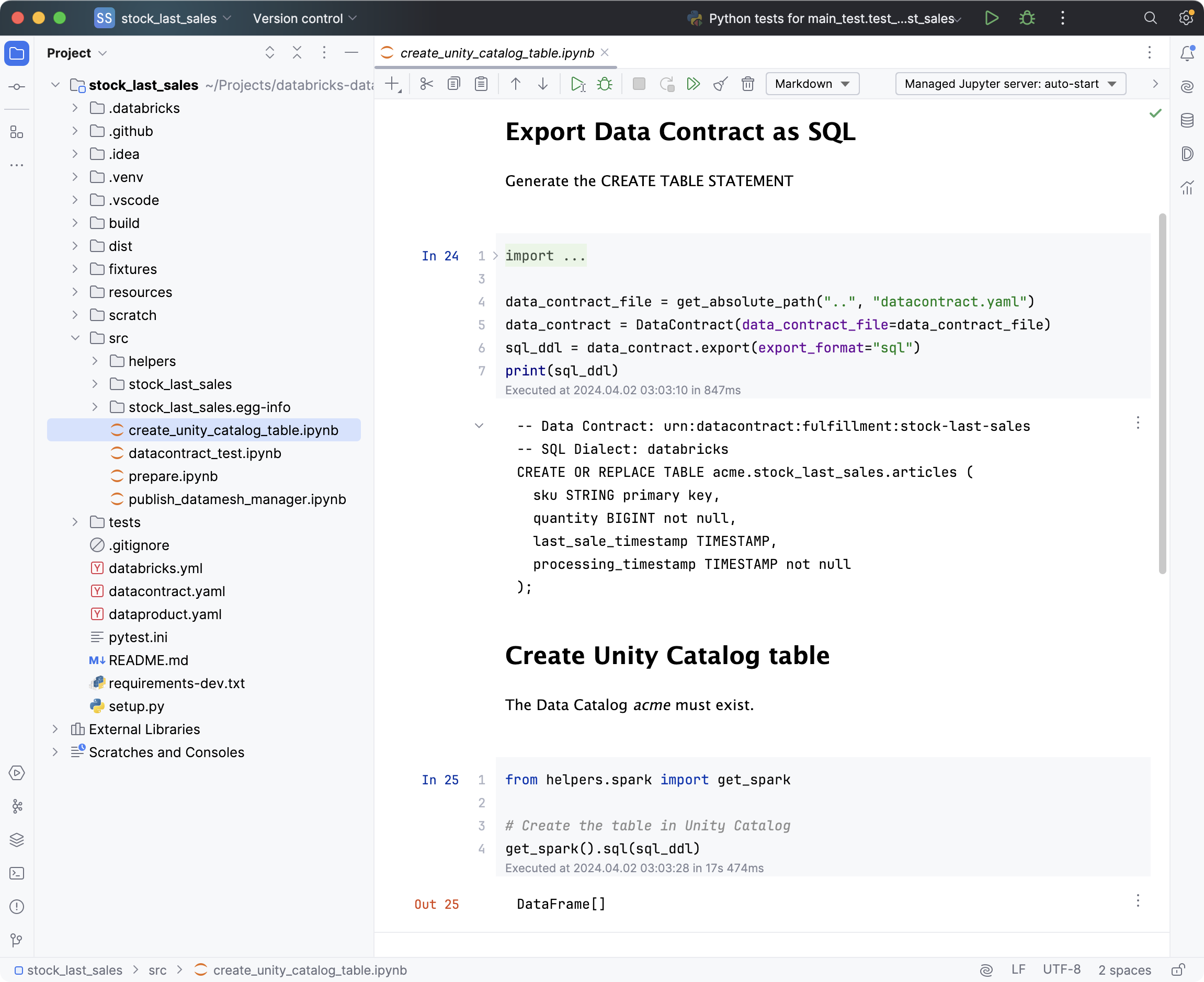
We can leverage the data contract YAML to generate infrastructure code:
The model defines the table structure of the target data model. With the Data Contract CLI tool, we can generate the SQL DDL code for the CREATE TABLE statement.
datacontract export --format sql datacontract.yaml
-- Data Contract: urn:datacontract:fulfillment:stock-last-sales
-- SQL Dialect: databricks
CREATE OR REPLACE TABLE acme.stock_last_sales.articles (
sku STRING primary key,
quantity BIGINT not null,
last_sale_timestamp TIMESTAMP,
processing_timestamp TIMESTAMP not null
);
The Data Contract CLI tool is also available as a Python Library
datacontract-cli. So let's add it to the requirements-dev.txt and use it in
directly in a Databricks notebook to actually create the table in Unity Catalog:
Develop Transformation Code
Now, let's write the core transformation logic. With Python-based Databricks Asset Bundles, we can develop our data pipelines as:
- Databricks Notebooks,
- Delta Live Tables, or
- Python files
In this data product, we'll write plain Python files for our core transformation logic that will be deployed as Wheel packages.
Our transformation takes all available stocks that we get from an input port, such as the operational system that manages the current stock data, and left-joins the dataframe with the latest sales timestamp for every sku. The sales information are also an input port, e.g., another upstream data product provided by the checkout team. We store the resulting dataframe in the previously generated table structure.
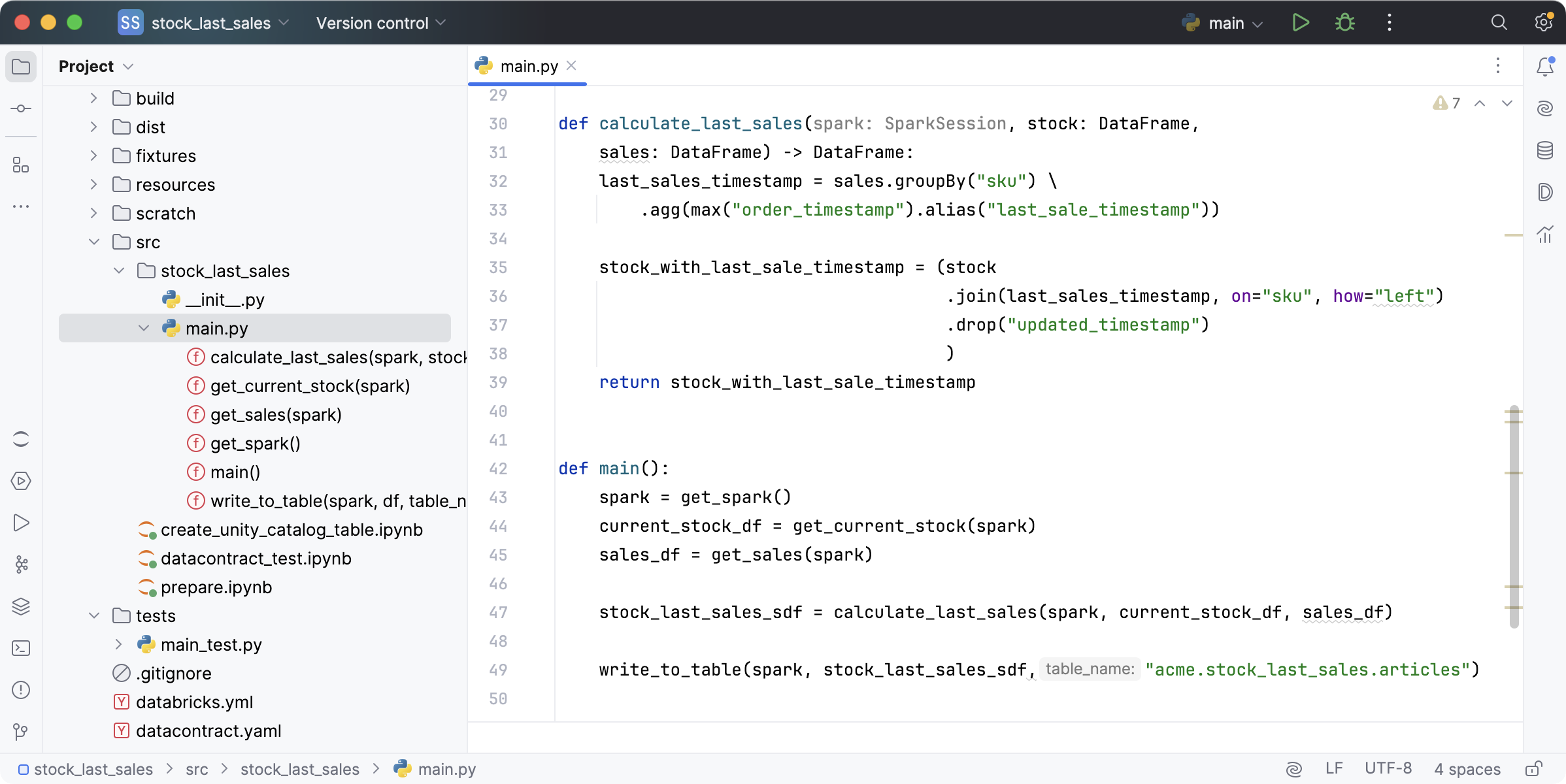
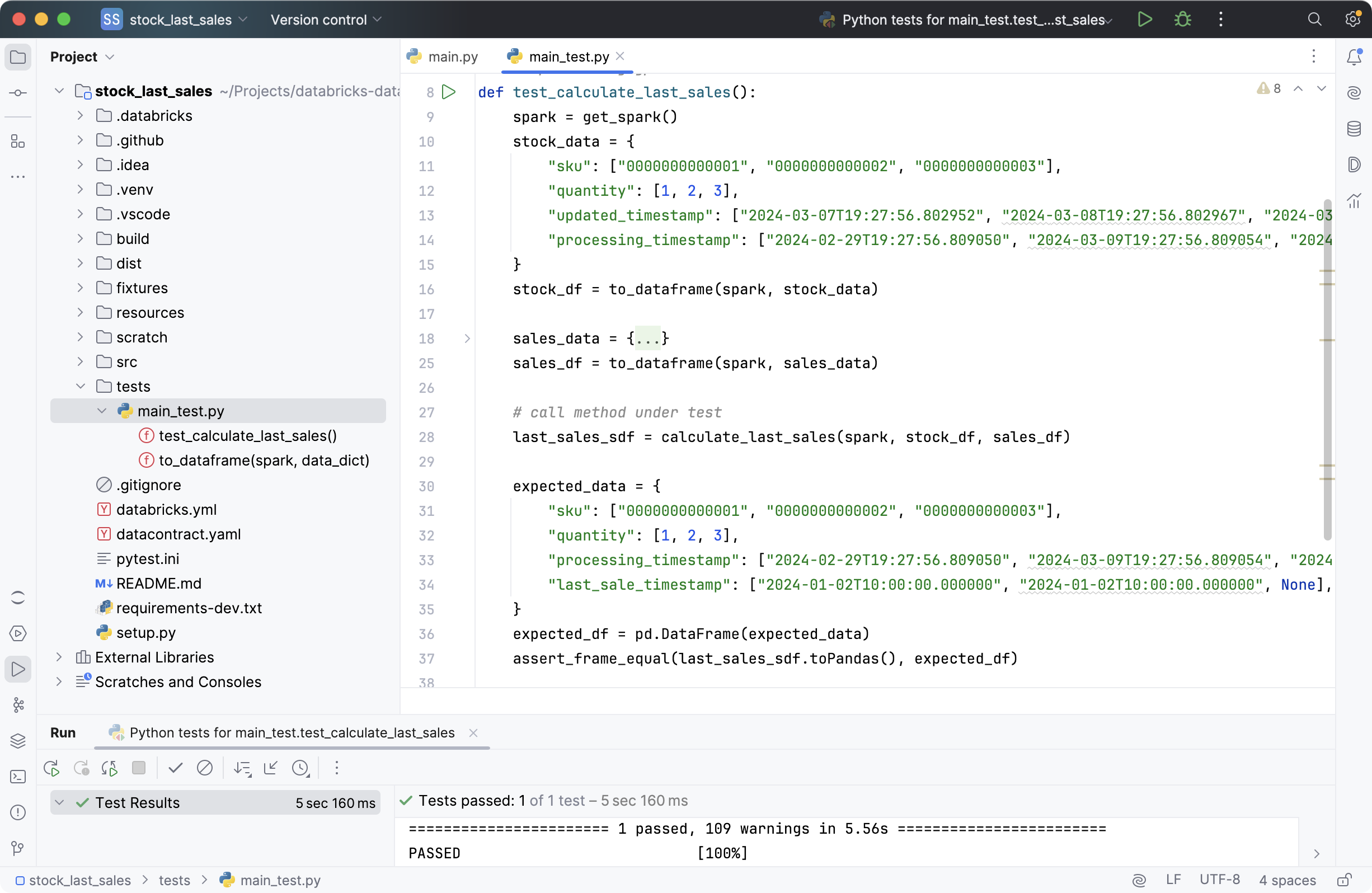
calculate_last_sales() function works as expected by writing good unit tests.
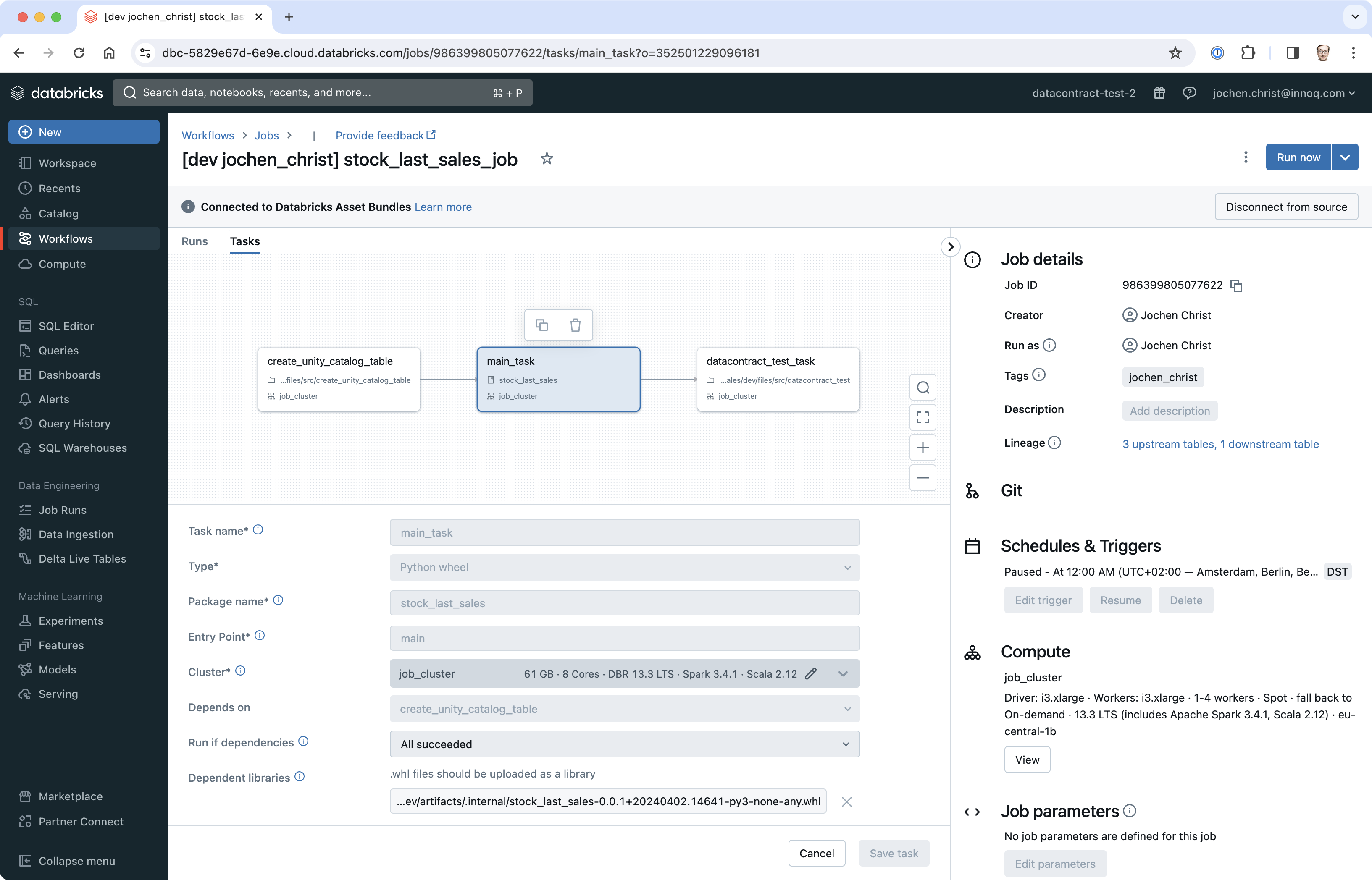
We update the job configuration to run the Python code as a python_wheel_task and configure the scheduler and the appropriate compute cluster.
# The main job for stock_last_sales.
resources:
jobs:
stock_last_sales_job:
name: stock_last_sales_job
schedule:
# Run every day at midnight
quartz_cron_expression: '0 0 0 * * ?'
timezone_id: Europe/Amsterdam
tasks:
- task_key: create_unity_catalog_table
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/create_unity_catalog_table.ipynb
libraries:
- pypi:
package: datacontract-cli
- task_key: main_task
depends_on:
- task_key: create_unity_catalog_table
job_cluster_key: job_cluster
python_wheel_task:
package_name: stock_last_sales
entry_point: main
libraries:
- whl: ../dist/*.whl
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: 4
When we are confident, we can deploy the bundle to our Databricks dev instances (manually for now):
databricks bundle deployAnd let's trigger a manual run of our workflow:
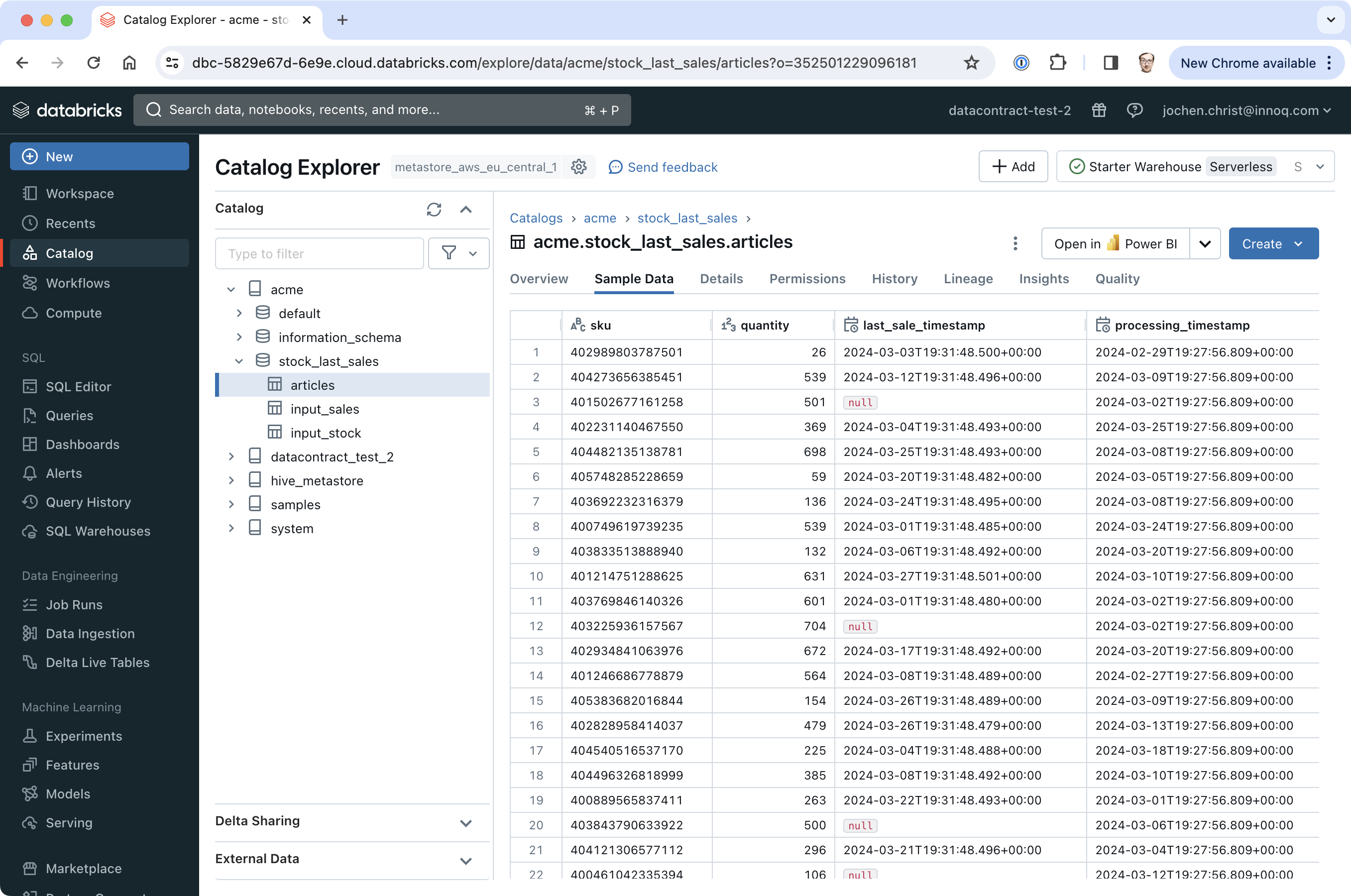
databricks bundle run stock_last_sales_jobIn Databricks, we can see that the workflow run was successful:
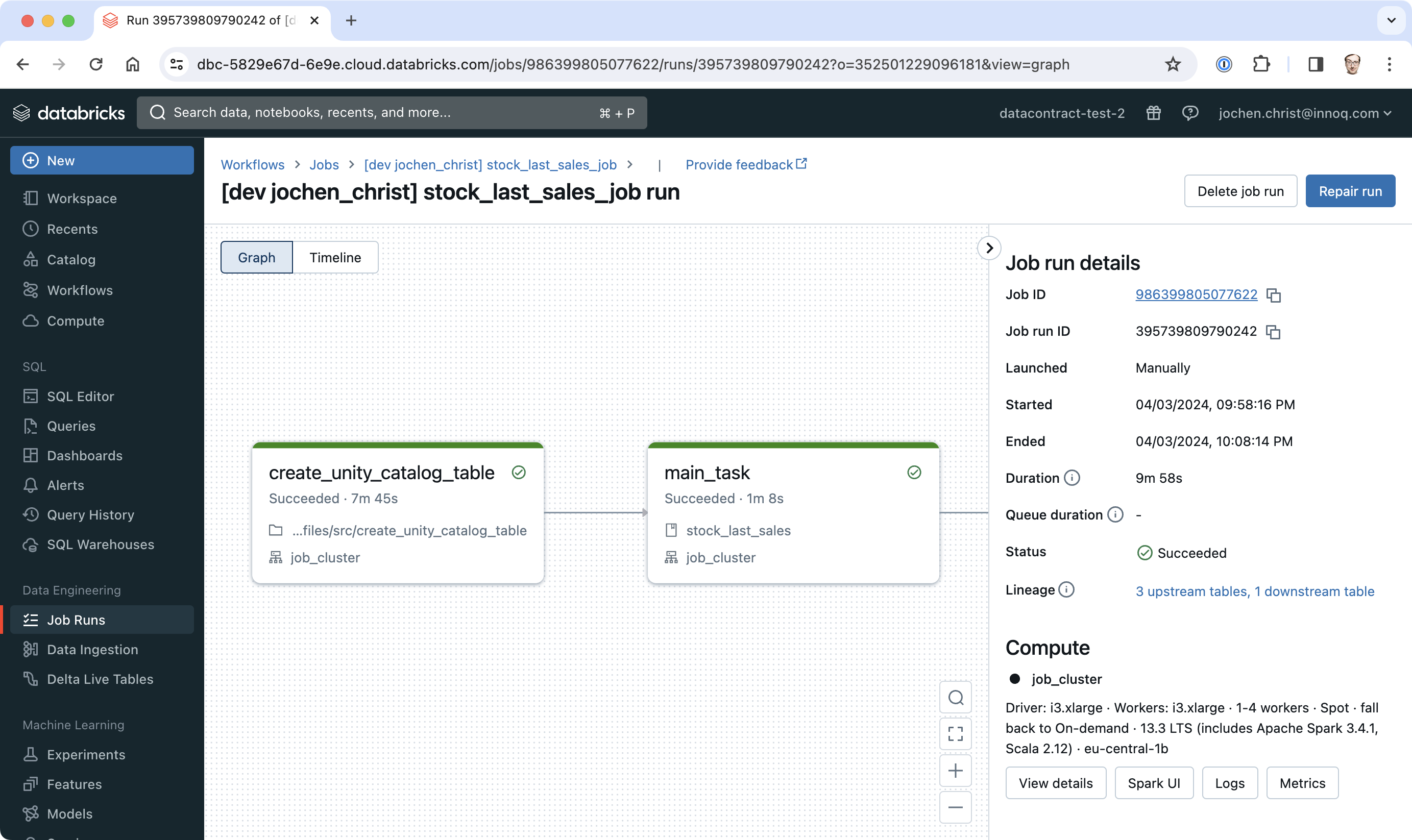
And we have data in our table that we created earlier.
Test the Data Contract
We are not quite finished with our task. How do we know, that the data is correct? While we have unit tests that give us confidence on the transformation code, we also need an acceptance test to verify, that we implemented the agreed data contract correctly.
For that, we can use the Data Contract CLI tool to make this check:
export DATACONTRACT_DATABRICKS_HTTP_PATH=/sql/1.0/warehouses/b053xxxxxxx
export DATACONTRACT_DATABRICKS_TOKEN=dapia1926f7c64b7595880909xxxxxxxxxx
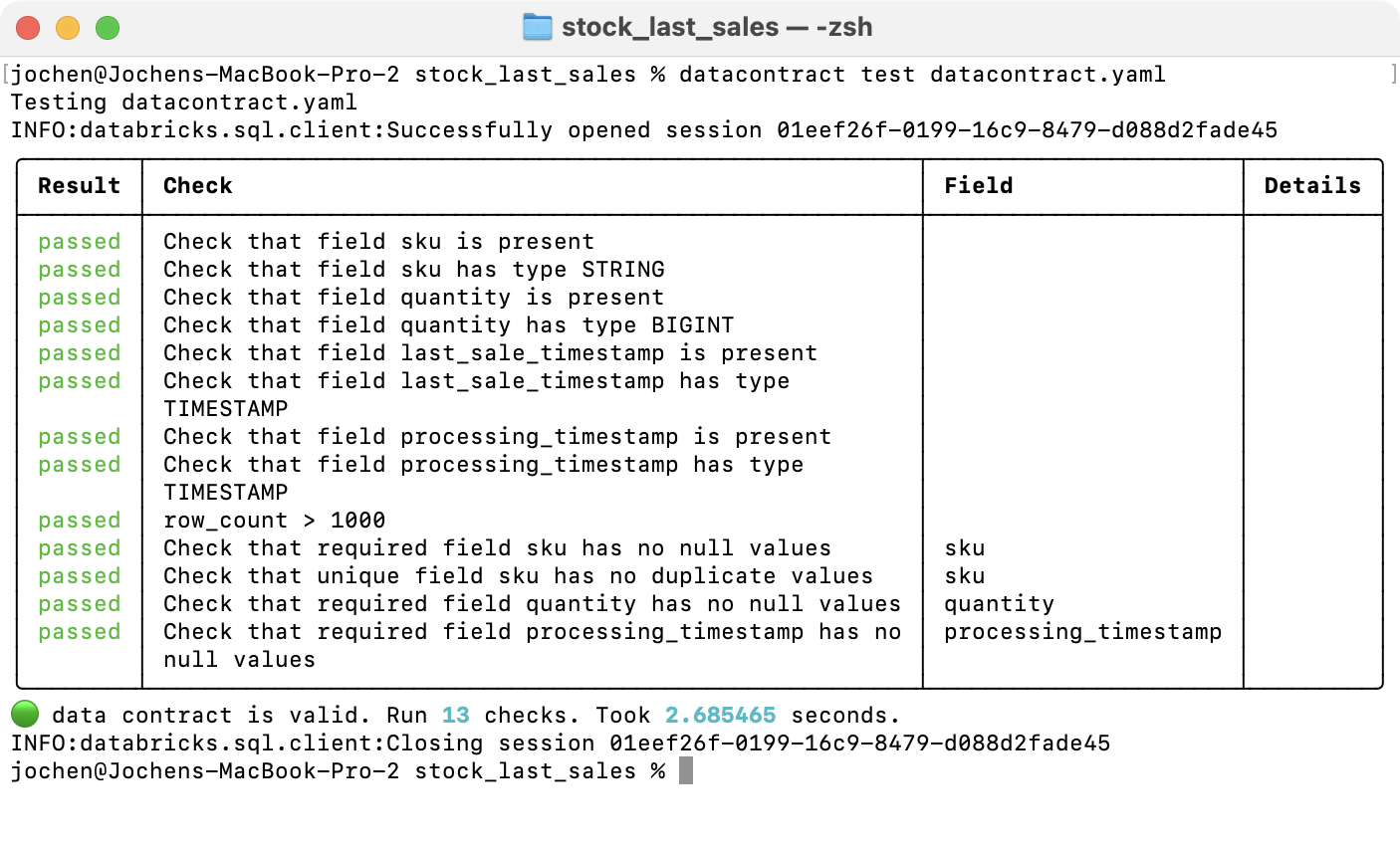
datacontract test datacontract.yaml
The datacontract tool takes all the schema and format information from the model,
the quality attributes, and the metadata, and compares them with the actual dataset. It
reads the connection details from the servers section and connects to Databricks
executes all the checks and gives a comprehensive overview.
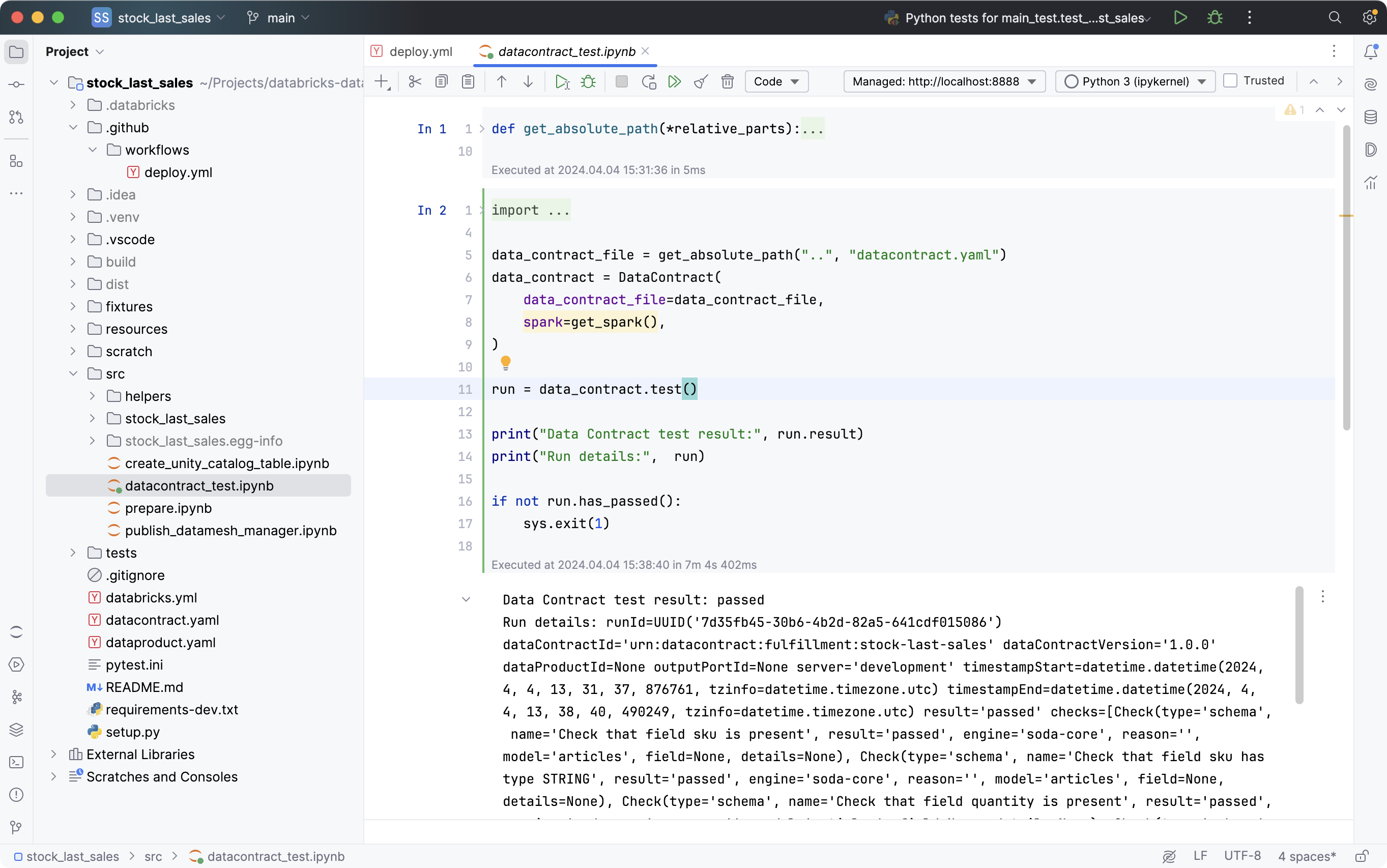
We want to execute this test with every pipeline run, so once again, let's make a Notebook task for the test:
Deploy with CI/CD
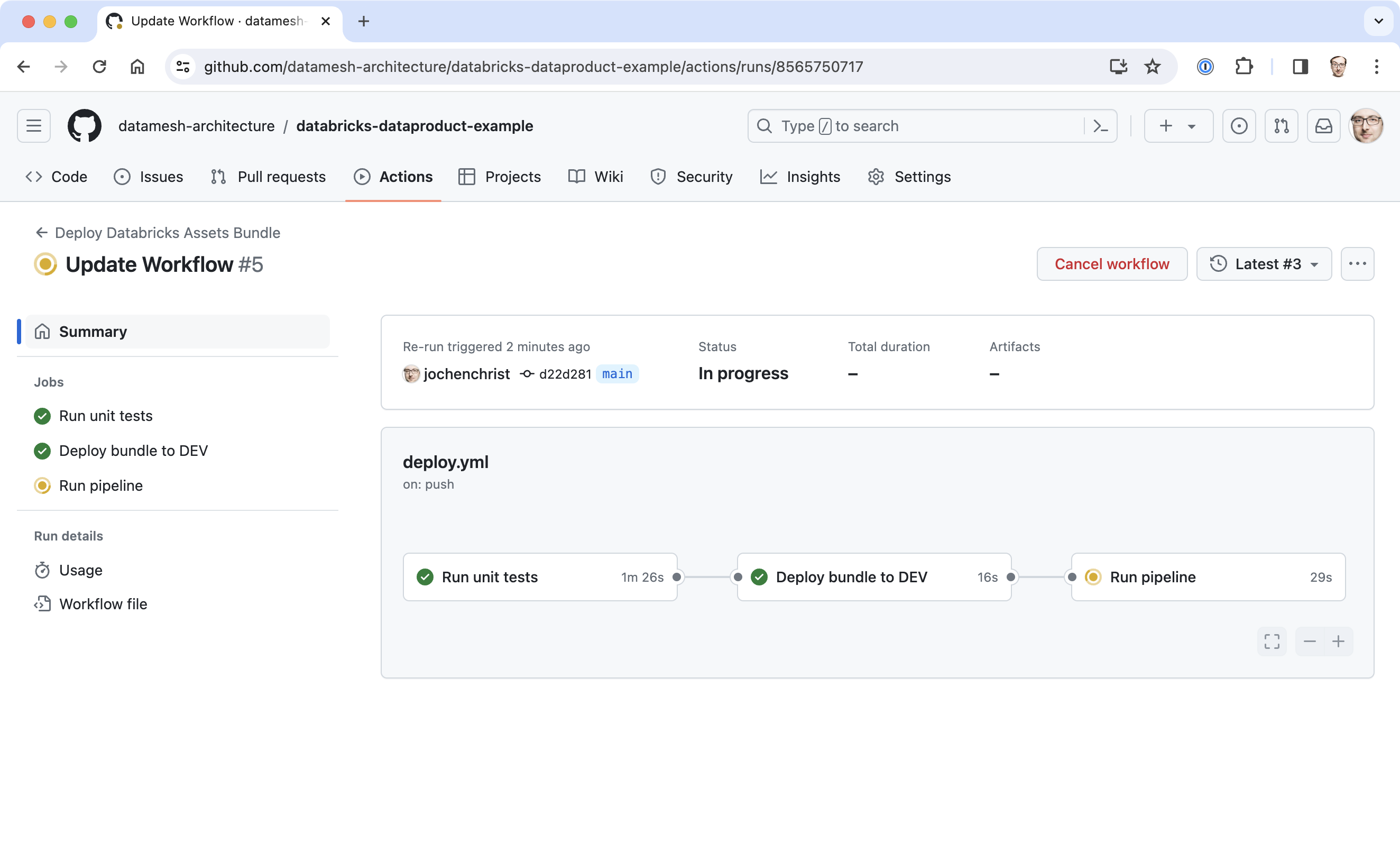
To automatically test, deploy the Asset Bundle to Databricks, and finally run the job once, we set up a CI/CD pipeline in GitHub, using a GitHub Action.
name: "Deploy Databricks Assets Bundle"
on:
workflow_dispatch:
push:
branches: [ "main" ]
jobs:
test:
name: "Run unit tests"
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python ${{matrix.python-version}}
uses: actions/setup-python@v5
with:
python-version: "3.10"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements-dev.txt
- name: Test with pytest
run: pytest
env:
DATABRICKS_HOST: ${{ secrets.DATABRICKS_HOST }}
DATABRICKS_TOKEN: ${{ secrets.SP_TOKEN }}
DATABRICKS_CLUSTER_ID: ${{ secrets.DATABRICKS_CLUSTER_ID }}
deploy:
name: "Deploy bundle to DEV"
runs-on: ubuntu-latest
needs:
- test
steps:
- uses: actions/checkout@v4
- uses: databricks/setup-cli@main
- run: databricks bundle deploy
working-directory: .
env:
DATABRICKS_TOKEN: ${{ secrets.SP_TOKEN }}
DATABRICKS_BUNDLE_ENV: dev
run_pipieline:
name: "Run pipeline"
runs-on: ubuntu-latest
needs:
- deploy
steps:
- uses: actions/checkout@v4
- uses: databricks/setup-cli@main
- run: databricks bundle run stock_last_sales_job --refresh-all
working-directory: .
env:
DATABRICKS_TOKEN: ${{ secrets.SP_TOKEN }}
DATABRICKS_BUNDLE_ENV: dev
Publish Metadata
For others to find, understand, and trust data products, we want to register them in a data product registry.
In this example, we use Data Mesh Manager, a platform to register, manage, and discover data products, data contracts, and global policies.
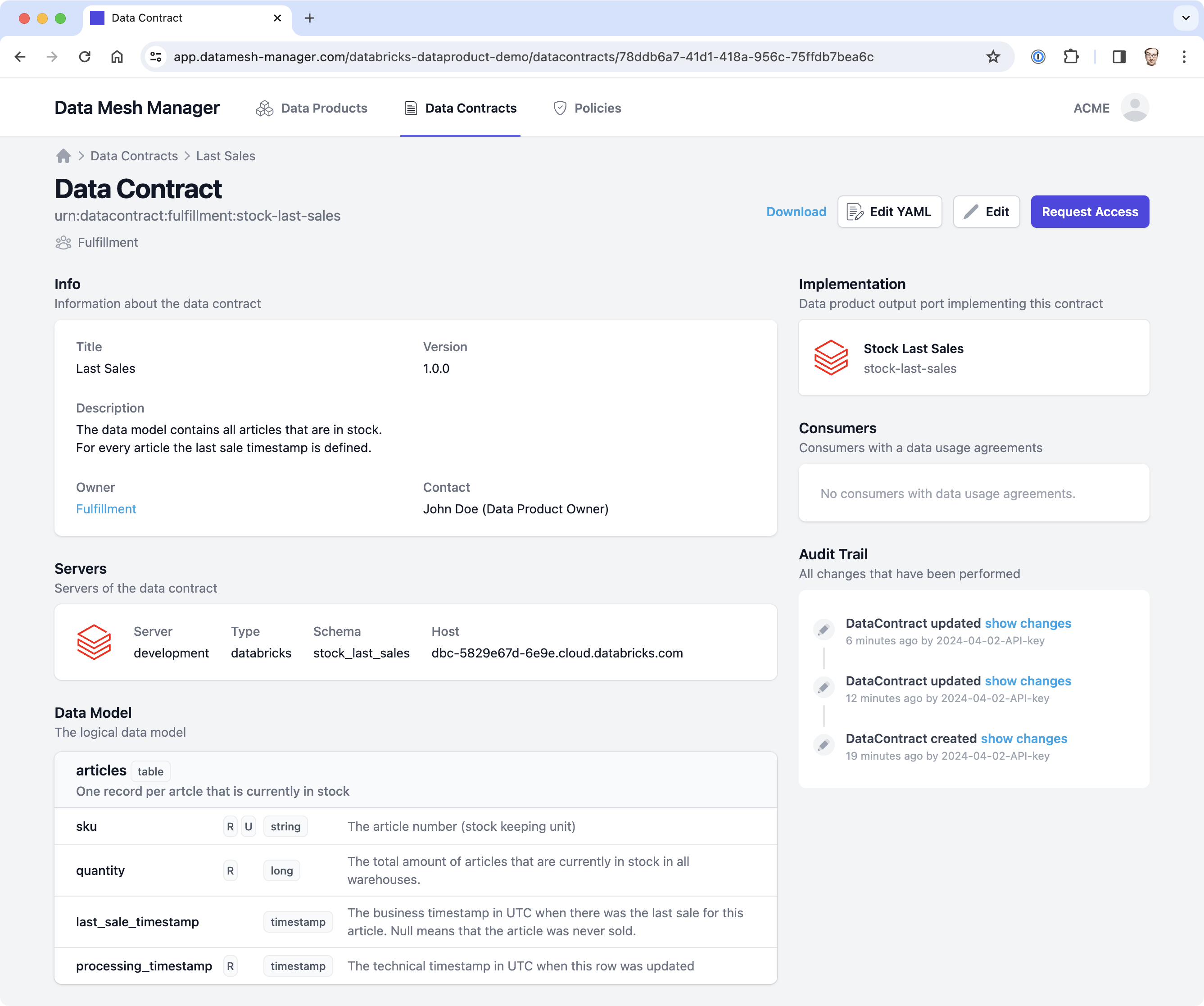
Again, let's create a notebook task (or Python code task) to publish the metadata to Data Mesh Manager and add the task to our workflow. We can use Databricks Secrets to make the API Key available in Databricks.
databricks secrets create-scope datamesh_manager
databricks secrets put-secret datamesh_manager api_key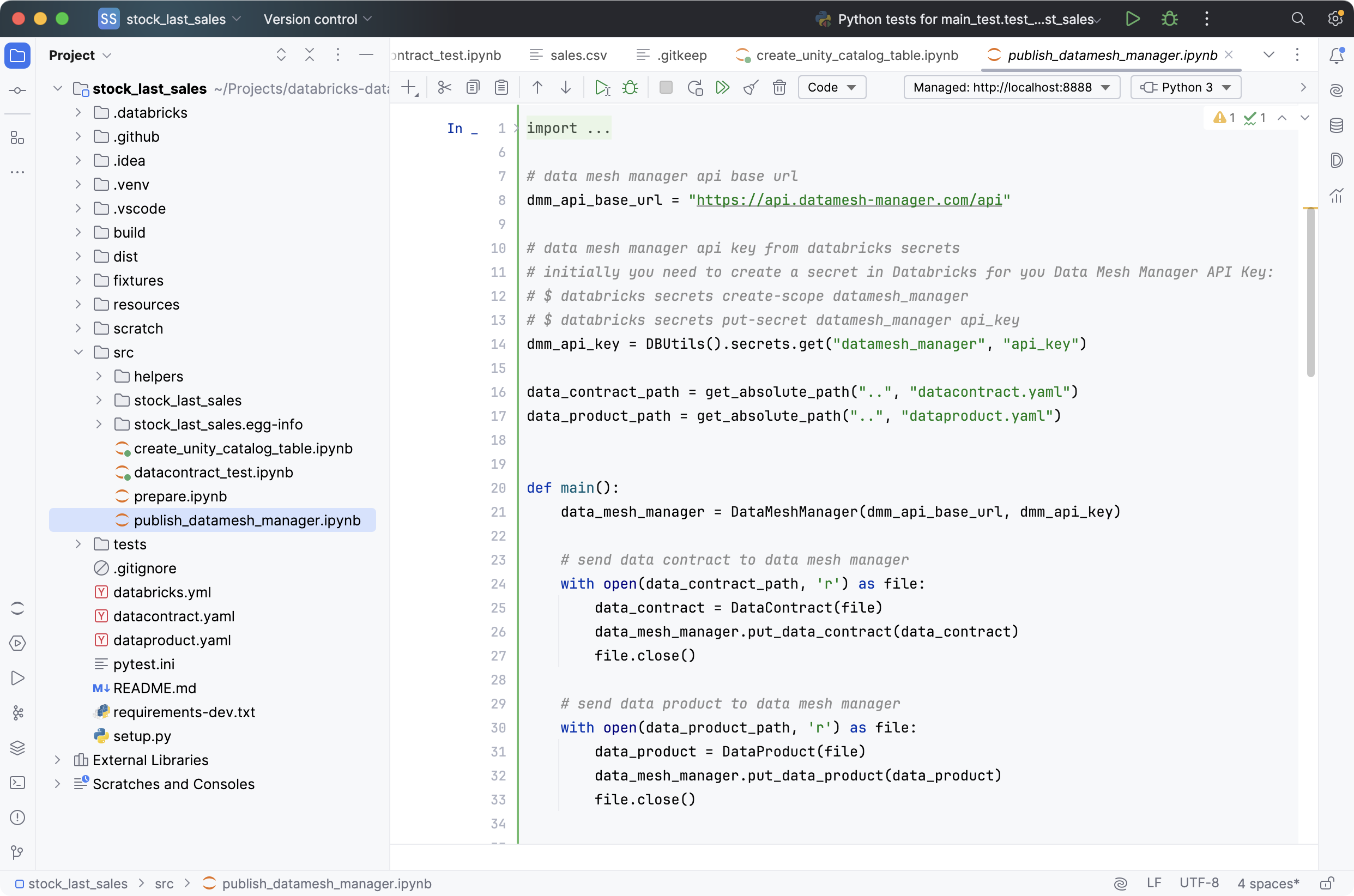
Summary
Now, the COO can connect to this table with a BI tool (such as PowerBI, Tableau, Redash, or withing Databricks) to answer their business question.
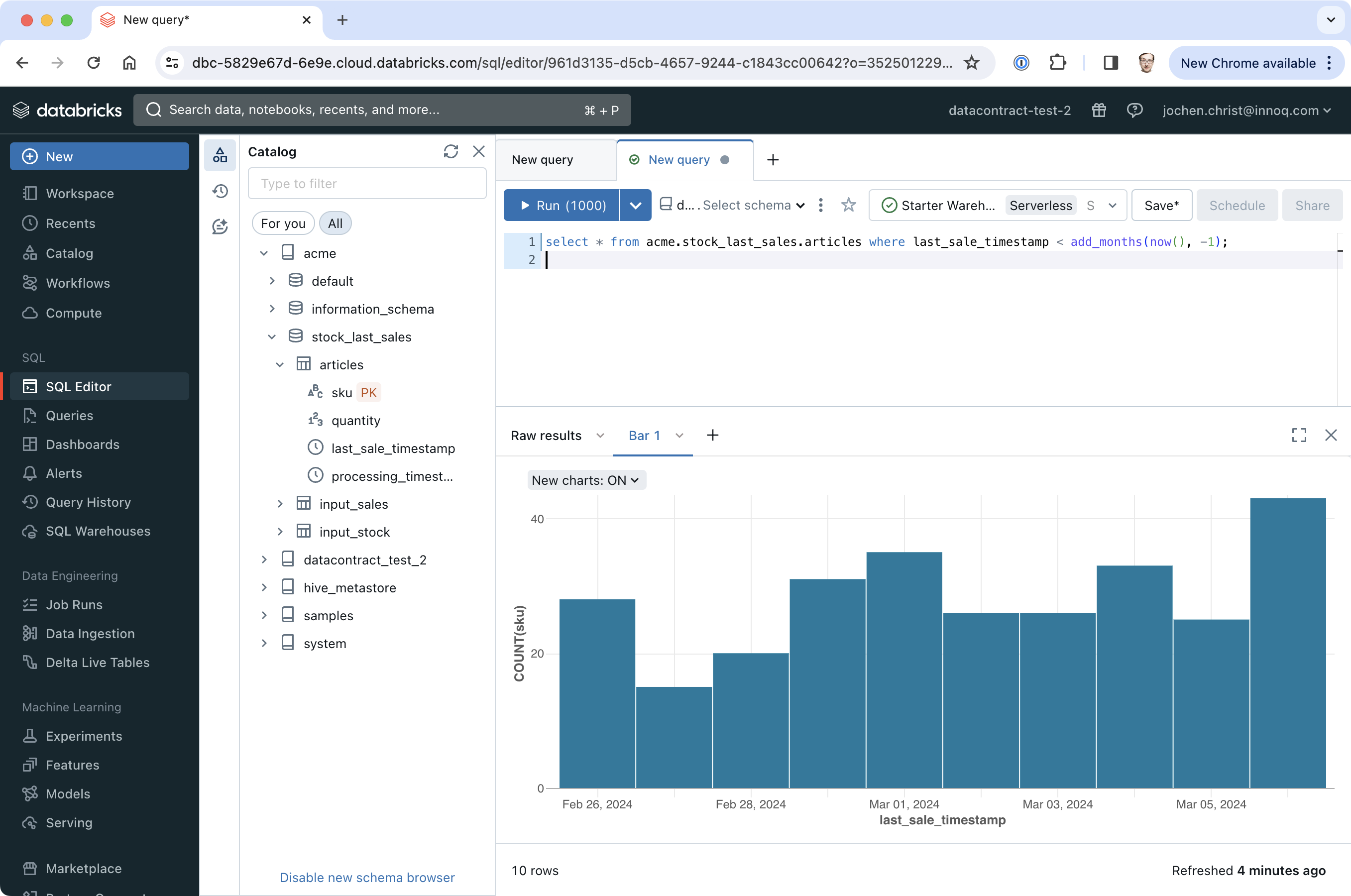
Databricks Asset Bundles are a great fit to develop professional data products on Databricks, as it bundles all the resources and configurations (code, tests, storage, compute, scheduler, metadata, ...) that are needed to provide high-quality datasets to data consumers.
It is easy to integration Data Contracts for defining the requirements and the Data Contract CLI to automate acceptance tests.
Find the source code for the example project on GitHub.
Learn More
- Source Code for the examples project
- Official databricks documentation on Databricks Asset Bundles
- Databricks Tech Stack
- Data Contract Specification
- Data Contract CLI
- Data Mesh Manager
